

一、深度学习的可解释性研究概述
随着深度学习模型在人们日常生活中的许多场景下扮演着越来越重要的角色,模型的「可解释性」成为了决定用户是否能够「信任」这些模型的关键因素(尤其是当我们需要机器为关系到人类生命健康、财产安全等重要任务给出预测和决策结果时)。在本章,我们将从深度学习可解释性的定义、研究意义、分类方法 3 个方面对这一话题展开讨论。
1.1
何为可解释性
对于深度学习的用户而言,模型的可解释性是一种较为主观的性质,我们无法通过严谨的数学表达方法形式化定义可解释性。通常,我们可以认为深度学习的可解释性刻画了「人类对模型决策或预测结果的理解程度」,即用户可以更容易地理解解释性较高的模型做出的决策和预测。
从哲学的角度来说,为了理解何为深度学习的可解释性,我们需要回答以下几个问题:首先,我们应该如何定义对事务的「解释」,怎样的解释才足够好?许多学者认为,要判断一个解释是否足够好,取决于这个解释需要回答的问题是什么。对于深度学习任务而言,我们最感兴趣的两类问题是「为什么会得到该结果」和「为什么结果应该是这样」。而理想状态下,如果我们能够通过溯因推理的方式恢复出模型计算出输出结果的过程,就可以实现较强的模型解释性。
实际上,我们可以从「可解释性」和「完整性」这两个方面来衡量一种解释是否合理。「可解释性」旨在通过一种人类能够理解的方式描述系统的内部结构,它与人类的认知、知识和偏见息息相关;而「完整性」旨在通过一种精确的方式来描述系统的各个操作步骤(例如,剖析深度学习网络中的数学操作和参数)。然而,不幸的是,我们很难同时实现很强的「可解释性」和「完整性」,这是因为精确的解释术语往往对于人们来说晦涩难懂。同时,仅仅使用人类能够理解的方式进行解释由往往会引入人类认知上的偏见。
此外,我们还可以从更宏大的角度理解「可解释性人工智能」,将其作为一个「人与智能体的交互」问题。如图 1 所示,人与智能体的交互涉及人工智能、社会科学、人机交互等领域。
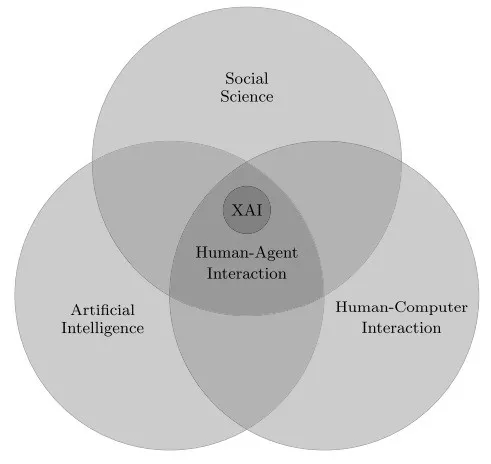
图 1:可解释的人工智能
1.2
为什么需要可解释性
在当下的深度学习浪潮中,许多新发表的工作都声称自己可以在目标任务上取得良好的性能。尽管如此,用户在诸如医疗、法律、金融等应用场景下仍然需要从更为详细和具象的角度理解得出结论的原因。为模型赋予较强的可解释性也有利于确保其公平性、隐私保护性能、鲁棒性,说明输入到输出之间个状态的因果关系,提升用户对产品的信任程度。下面,我们从「完善深度学习模型」、「深度学习模型与人的关系」、「深度学习模型与社会的关系」3 个方面简介研究机器深度学习可解释性的意义。
(1)完善深度学习模型
大多数深度学习模型是由数据驱动的黑盒模型,而这些模型本身成为了知识的来源,模型能提取到怎样的知识在很大程度上依赖于模型的组织架构、对数据的表征方式,对模型的可解释性可以显式地捕获这些知识。
尽管深度学习模型可以取得优异的性能,但是由于我们难以对深度学习模型进行调试,使其质量保证工作难以实现。对错误结果的解释可以为修复系统提供指导。
(2)深度学习模型与人的关系
在人与深度学习模型交互的过程中,会形成经过组织的知识结构来为用户解释模型复杂的工作机制,即「心理模型」。为了让用户得到更好的交互体验,满足其好奇心,就需要赋予模型较强的可解释性,否则用户会感到沮丧,失去对模型的信任和使用兴趣。
人们希望协调自身的知识结构要素之间的矛盾或不一致性。如果机器做出了与人的意愿有出入的决策,用户则会试图解释这种差异。当机器的决策对人的生活影响越大时,对于这种决策的解释就更为重要。
当模型的决策和预测结果对用户的生活会产生重要影响时,对模型的可解释性与用户对模型的信任程度息息相关。例如,对于医疗、自动驾驶等与人们的生命健康紧密相关的任务,以及保险、金融、理财、法律等与用户财产安全相关的任务,用户往往需要模型具有很强的可解释性才会谨慎地采用该模型。
(3)深度学习模型与社会的关系
由于深度学习高度依赖于训练数据,而训练数据往往并不是无偏的,会产生对于人种、性别、职业等因素的偏见。为了保证模型的公平性,用户会要求深度学习模型具有检测偏见的功能,能够通过对自身决策的解释说明其公平。
深度学习模型作为一种商品具有很强的社会交互属性,具有强可解释性的模型也会具有较高的社会认可度,会更容易被公众所接纳。
1.3
可解释性的分类
根据可解释性方法的作用时间、可解释性方法与模型的匹配关系、可解释性方法的作用范围,我们可以将深度学习的可解释性方法分为:本质可解释性和事后可解释性、针对特定模型的可解释性和模型无关可解释性、局部可解释性和全局可解释性。
其中,本质可解释性指的是对模型的架构进行限制,使其工作原理和中间结果能够较为容易地为人们所理解(例如,结构简单的决策树模型);事后可解释性则指的是通过各种统计量、可视化方法、因果推理等手段,对训练后的模型进行解释。
由于深度模型的广泛应用,本文将重点关注深度学习的可解释性,并同时设计一些深度学习方法的解释。
二、深度学习的可解释性
对于深度学习模型来说,我们重点关注如何解释「网络对于数据的处理过程」、「网络对于数据的表征」,以及「如何构建能够生成自我解释的深度学习系统」。网路对于数据的处理过程将回答「输入为什么会得到相应的的特定输出?」,这一解释过程与剖析程序的执行过程相类似;网络对于数据的表征将回答「网络包含哪些信息?」,这一过程与解释程序内部的数据结构相似。下文将重点从以上三个方面展开讨论。
2.1
深度学习过程的可解释性
常用的深度网络使用大量的基本操作来得出决策:例如,ResNet使用了约5×107个学习参数,1010个浮点运算来对单个图像进行分类。解释这种复杂模型的基本方法是降低其复杂度。这可以通过设计表现与原始模型相似但更易于解释的代理模型来完成(线性代理模型、决策树模型等),或者也可以构建显著性图(salience map),来突出显示最相关的一部分计算,从而提供可解释性。
(1)线性代理模型(Proxy Models)
目前被广泛采用的深度学习模型,大多仍然是「黑盒模型」。在根据预测结果规划行动方案,或者选择是否部署某个新模型时,我们需要理解预测背后的推理过程,从而评估模型的可信赖程度。一种可能的方法是,使用线性可解释的模型近似“黑盒模型”。
Marco et. al [1]提出了一种新的模型无关的模型解释技术「LIME」,它可以通过一种可解释的、准确可靠的方式,通过学习一个围绕预测结果的可解释模型,解释任意的分类器或回归模型的预测结果。本文作者还通过简洁地展示具有代表性的个体预测结果及其解释,将该任务设计成了一种子模块优化问题。
文中指出,一种优秀的解释方法需要具备以下几点特质:
(1)可解释性:给出对输入变量和响应的关系的定性理解,可解释性需要考虑用户自身的限制。
(2)局部保真:解释方法至少需要在局部是可靠的,它必须与模型在被预测实例附近的表现相对应。需要指出的是,在全局上重要的特征不一定在局部环境下仍然重要,反之亦然。
(3)模型无关:解释方法需要能够解释各种各样的模型。
(4)全局视角:准确度有时并不是一个很好的模型评价指标,解释器旨在给出一些具有代表性的对样本的解释。
文中的方法可以基于对分类器局部可靠的可解释表征,来鉴别器模型的可解释性。LIME 会对输入样本进行扰动,识别出对于预测结果影响最大的特征(人类可以理解这些特征)。
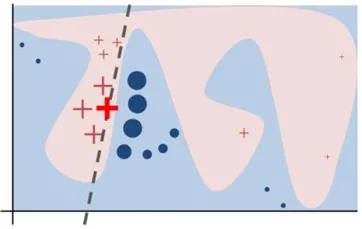
图 2
如图 2 所示,加粗的红色十字样本有待解释。从全局来看,很难判断红色十字和蓝色圆圈对于带解释样本的影响。我们可以将视野缩小到黑色虚线周围的局部范围内,在加粗红色十字样本周围对原始样本特征做一些扰动,将扰动后的采样样本作为分类模型的输入,LIME 的目标函数如下:
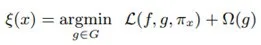
其中,f 为分类器,g 为解释器,π_x 为临近度度量,Ω(g) 为解释器 g 的复杂度,L 为损失函数。
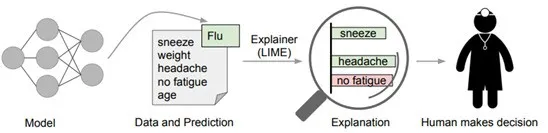
图 3
因为代理模型提供了模型复杂度与可信度之间的量化方法,因此方法间可以互相作为参考,吸引了许多研究工作。
(2)决策树方法
另一种代理模型的方法是决策树。将神经网络分解成决策树的工作从1990年代开始,该工作能够解释浅层网络,并逐渐泛化到深度神经网络的计算过程中。
一个经典的例子是Makoto et. al [2]。文中提出了一种新的规则抽取(Rule Extraction)方法CRED,使用决策树对神经网络进行分解,并通过c/d-rule算法合并生成的分支,产生不同分类粒度,能够考虑连续与离散值的神经网络输入输出的解释。具体算法如下:
一.将网络输入变量按设定的特征间隔大小分成不同类别,并划分网络的目标输出和其他输出。
二.建立输出隐藏决策树(Hidden-Output Decision Tree)每个结点使用预测目标的特征做区分,以此分解网络,建立网络的中间规则。三.对于2建立的每个节点,对其代表的每个函数建立输入隐藏决策树(Hidden-Input Decision Tree),对输入的特征进行区分,得到每个节点输入的规则。四.使用3中建立的输入规则替换结点的输出规则,得到网络整体的规则。五.合并结点,根据设定的规则,使表达简洁。
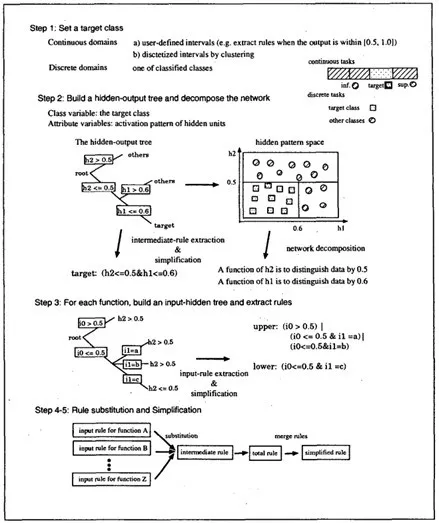
图 4 :CRED算法
DeepRED [3]将CRED的工作拓展到了多层网络上,并采用了多种结构优化生成树的结构。另一种决策树结构是ANN-DT[4],同样使用模型的结点结构建立决策树,对数据进行划分。不同的是,判断节点是采用正负两种方法判断该位置的函数是否被激活,以此划分数据。决策树生成后,通过在样本空间采样、实验,获得神经网络的规则。
这阶段的工作对较浅的网络生成了可靠的解释,启发了很多工作,但由于决策树节点个数依赖于网络大小,对于大规模的网络,方法的计算开销将相应增长。
(3)自动规则生成
自动规则生成是另一种总结模型决策规律的方法,上世纪80年代, Gallant将神经网络视作存储知识的数据库,为了从网络中发掘信息和规则,他在工作[4]中提出了从简单网络中提取规则的方法,这可以被看作是规则抽取在神经网络中应用的起源。现今,神经网络中的规则生成技术主要讲输出看作规则的集合,利用命题逻辑等方法从中获取规则。
Hiroshi Tsukimoto [6]提出了一种从训练完成的神经网络中提取特征提取规则的方法,该方法属于分解法,可以适用在输出单调的神经网络中,如sigmoid函数。该方法不依赖训练算法,计算复杂度为多项式,其计算思想为:用布尔函数拟合神经网络的神经元,同时为了解决该方法导致计算复杂度指数增加的问题,将算法采用多项式表达。最后将该算法推广到连续域,提取规则采用了连续布尔函数。
Towell [7]形式化了从神经网络中提取特征的方法,文章从训练完成的神经网络中提取网络提取特征的方法,MoFN,该方法的提取规则与所提取的网络的精度相近,同时优于直接细化规则的方法产生的规则,更加利于人类理解网络。
MoFN分为6步:1)聚类;2)求平均;3)去误差;4)优化;5)提取;6)简化。
聚类采用标准聚类方法,一次组合两个相近的族进行聚类,聚类结束后对聚类的结果进行求平均处理,计算时将每组中所有链路的权重设置为每个组权重的平均值,接下来将链接权重较低的组去除,将留下的组进行单位偏差优化,优化后的组进行提取工作,通过直接将每个单元的偏差和传入权重转换成具有加权前因的规则来创建,最后对提取到的规则简化。MOFN的算法示例如下图所示。
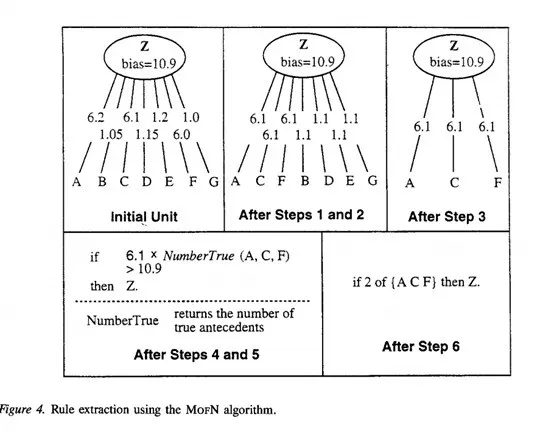
图5:MOFN 算法
规则生成可以总结出可靠可信的神经网络的计算规则,他们有些是基于统计分析,或者是从模型中推导,在保障神经网络在关键领域的应用提供了安全保障的可能。
(4)显著性图
显著性图方法使用一系列可视化的技术,从模型中生成解释,该解释通常表达了样本特征对于模型输出的影响,从而一定程度上解释模型的预测。常见方法有反卷积、梯度方法等。Zeiler [8]提出了可视化的技巧,使用反卷积观察到训练过程中特征的演化和影响,对CNN内部结构与参数进行了一定的“解读”,可以分析模型潜在的问题,网络深度、宽度、数据集大小对网络性能的影响,也可以分析了网络输出特征的泛化能力以及泛化过程中出现的问题。
利用反卷积实现特征可视化
为了解释卷积神经网络如何工作,就需要解释CNN的每一层学习到了什么东西。为了理解网络中间的每一层,提取到特征,论文通过反卷积的方法,进行可视化。反卷积网络可以看成是卷积网络的逆过程。反卷积可视化以各层得到的特征图作为输入,进行反卷积,得到反卷积结果,用以验证显示各层提取到的特征图。
Eg:假如你想要查看Alexnet的conv5提取到了什么东西,就用conv5的特征图后面接一个反卷积网络,然后通过:反池化、反激活、反卷积,这样的一个过程,把本来一张13*13大小的特征图(conv5大小为13*13),放大回去,最后得到一张与原始输入图片一样大小的图片(227*227)。
反池化过程
池化是不可逆的过程,然而可以通过记录池化过程中,最大激活值的坐标位置。然后在反池化的时候,只把池化过程中最大激活值所在的位置坐标的值激活,其它的值置为0,当然这个过程只是一种近似,因为在池化的过程中,除了最大值所在的位置,其它的值也是不为0的。
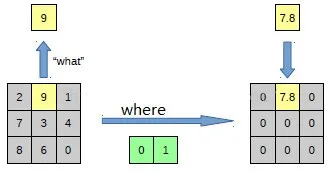
图 6
反激活
在Alexnet中,relu函数是用于保证每层输出的激活值都是正数,因此对于反向过程,同样需要保证每层的特征图为正值,也就是说这个反激活过程和激活过程没有什么差别,都是直接采用relu函数。
另一些可视化方法可视化方法主要是通过deconv的方法将某一层特征图的Top-k激活反向投射到原图像上,从而判断该激活值主要识别图像的什么部分。这就要求针对每一层都必须有对应的逆向操作。
具体而言,对于MaxPooling层,在前馈时使用switch变量来记录最大值来源的index,然后以此近似得到Unpooling。对于Relu层,直接使用Relu层。而对于conv层,使用deconv,即使用原来卷积核的转置作为卷积核。通过可视化方法,对训练完成的模型在ImageNet的数据各层可视化后,可以得到不同结构的重建特征图,与原图进行对比能够直观地看到网络各层学习到的信息:

图 7:第二层学习边缘,角落信息;第三层学到了一些比较复杂的模式,网状,轮胎;第四层展示了一些比较明显的变化,但是与类别更加相关了,比如狗脸,鸟腿;第五层则看到了整个物体,比如键盘,狗。
同时,通过可视化,我们也可以发现模型的缺陷,例如某些层学习到的特征杂乱无章,通过单独训练,可以提升模型效果。另外的方法也被采用,例如使用遮挡的方法,通过覆盖输入的某部分特征,分析输出和模型计算的中间参数,得到模型对被遮挡部分的敏感性,生成敏感性图,或者用梯度方法得到输出对于输入图像像素的梯度,生成梯度热力图。
总结性的工作来自ETH Zurch的Enea Ceolini [9]证明了基于梯度的归因方法(gradient-based Attribution methods)存在形式上\联系,文章证明了在一定情况下,诸如sigma-LRP[10]、DeepLIF[11]方法间存在的等价和近似关系,并基于统一的数学表达,提出了一个更普适的梯度归因方法框架Sensitivity-n,用于解释模型输入输出之间的关联。
深度学习的归因分析用于解释输入的每个变量对于神经网络的贡献(contribution),或相关程度(relevance),严格来说,假设网络的输入为x = [x1, ..., xN ],C个输出神经元对应的输出为S(x) = [S1(x), ..., SC (x)],归因分析的目标便是找到xi对于每个神经元输出的贡献,Rc = [Rc 1 , ..., Rc N ]。
基于梯度的方法可以被看作直接使用输出对输出的特征求梯度,用梯度的一定变换形式表示其重要性,工作中展示的考虑不同大小特征区域热力图如下:

图 8
文章分析了不同方法的效果差异:

图 9
通过证明,得到通用的梯度方法表示为:
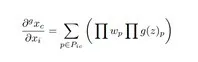
基于上述推导,作者得以提出了sensitivity-n方法,总结了相似的梯度方法,并使后续工作可以在更广泛的框架下讨论。
2.2
深度网络表示的可解释性
尽管存在大量神经网络运算,深度神经网络内部由少数的子组件构成:例如,数十亿个ResNet的操作被组织为约100层,每层计算64至2048信息通道像素。对深层网络表示的解释旨在了解流经这些信息瓶颈的数据的作用和结构。可以按其粒度划分为三个子类:基于层的解释,将流经层的所有信息一起考虑;基于神经元的解释,用来说明单个神经元或单个filter通道的情况;此外基于(其他)表示向量的解释,例如概念激活向量(CAV)[12]是通过识别和探测与人类可解释概念一致的方向来解释神经网络表示,用单个单元的线性组合所形成的表示向量空间中的其他方向作为其表征向量。
(1)基于层的解释
Bengio等人[13]分析了在图片分类任务中,不同层的神经网络的功能和可迁移性,以及不同迁移方法对结果的影响。从实验的角度分析了神经网络不同层参数具有的一些性质,证明了模型迁移方法的普遍效果。作者验证了浅层神经网络在特征抽取功能上的通用性和可复用性,针对实验结果提出了可能的解释,表明影响迁移学习效果的因素有二:
1) 共同训练变量的影响
通过反向传播算法训练的神经网络,结点参数并非单独训练,其梯度计算依赖于一系列相关结点,因此迁移部分结点参数会引起相关结点的训练困难。
2) 迁移参数的通用性能和专用性
网络中较浅层网络的功能较为通用,而高层网络与网络的训练目标更加相关。若A、B任务不想关,则专用于A的参数迁移后会影响对B任务的学习。

图10
实验结果发现,在不同的实验条件下,两种因素会不同程度决定迁移学习的效果。例如,当迁移较深层网络并固定参数时,高层参数的专用性会导致在迁移到的任务上表现不佳,但这时共同训练的变量影响会减小,因为大部分参数都被迁移获得;当迁移自身的参数并固定时,在层数较小的情况下出现了性能下降,这说明了共同训练的变量对表现的影响。另外,实验发现完全不相关的任务对应的迁移,在经过充分微调后仍然能提升模型的性能,这证明了参数迁移是一个通用的提升模型性能的方法。
牛津大学Karen Simonyan等人[14]为解决深层卷积神经网络分类模型的可视化问题,提出了两种方法:第一种生成图像使得类得分最大化,再将类可视化;第二种计算给定图像和类的类显著性映射,同时还证明了这种方法可以使用分类转换网络的弱监督对象分类。整个文章主要有三个贡献:证明了理解分类CNN模型可以使用输入图像的数值优化;提出了一种在图像中提取指定类别的空间表征信息(image-specific class saliency map)的方法(只通过一次back-propagation),并且这种saliency maps可以用于弱监督的物体定位。证明gradient-based的可视化方法可以推广到deconvolutional network的重构过程。
在第一类方法中,文中采用公式(1)进行图像分类模型的可视化操作,由ConvNet的分类层对图像I计算得到,是正则化参数。可视化过程与ConvNet训练过程类似,不同之处在于对图像的输入做了优化,权重则固定为训练阶段得到的权重。图1所示为使用零图像初始化优化,然后将训练集的均值图像添加到结果中的输出图。
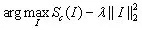
(1)
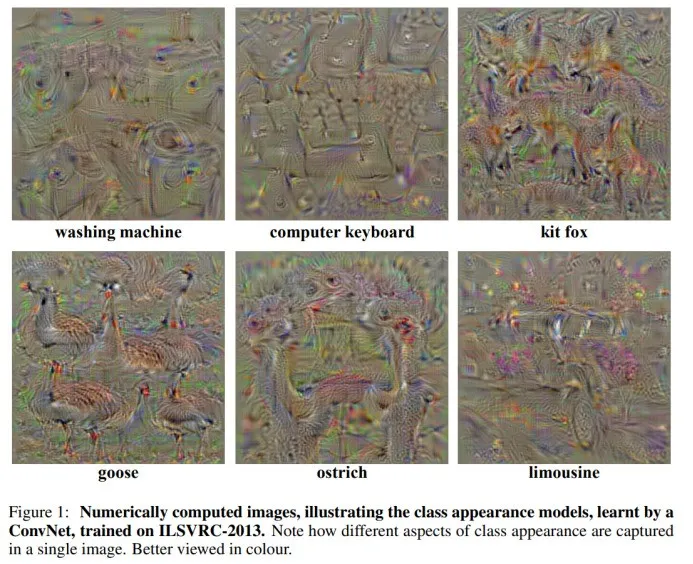
图 11
在第二类方法中,给定一张图像I0,在I0附近使用一阶泰勒展开的线性函数来近似Sc(I)
在给定的图像I0(m行n列)和对应的类别c中,要求得它对应saliency map M (M∈Rmxn),首先按照上述公式利用back-propagation 可以求得导数w,然后对w元素进行重新排列即可得到Saliency Map。Saliency Map是利用训练好的CNN直接提取的,无需使用额外的标注,而且对于某个特定类别的image-specific saliency map的求解是很快的,只需要一次back-propagation。可视化结果如图2所示

图 12
在第二类方法中得到的Saliency Map编码了给定图像中特定类别的物体位置信息,所以它可以被用来进行物体定位(尽管它在分类任务上得到训练,弱监督学习)。给定一张图像和其对应的Saliency Map,可以使用GraphCut颜色分割模型来得到物体分割mask。要使用颜色分割模型主要是因为Saliency Map只能捕捉到一个物体最具有区分性的部分,它无法highlight整个物体,因此需要将threshold map传递到物体的其他区域,本文使用colour continuity cues来达到这个目的。前景和背景模型都被设置为高式混合模型,高于图像Saliency distribution 95%的像素被视为前景,Saliency低于30%的像素被视为背景。标记了前景和背景像素之后,前景像素的最大连接区域即为对应物体的分割mask(使用GraphCut算法),效果如图3所示。

图 13
此外,Zhang et. al. 的工作[15]发现网络浅层具有统计输入信息的功能,并发现其和共享的特征信息一样,对迁移带来的性能提升起到了帮助。通过从相同checkpoint训练,发现参数迁移,可以使模型损失每次都保持在相同的平面内(basin),具有相似的地形,但随机初始化的参数每次损失所在的训练平面不同。文章支持了高层、低层网络具有的不同功能,发现高层网路对于参数的改变更加敏感。
(2)基于神经元的解释
香港中文大学助理教授周博磊的工作[16]为 CAM 技术的奠定了基础,发现了 CNN 中卷积层对目标的定位功能。在改文中,作者对场景分类任务中训练 CNN 时得到的目标检测器展开了研究。由于场景是由物体组成的,用于场景分类的 CNN 会自动发现有意义的目标检测器,它们对学到的场景类别具有代表性。作者发现,单个网络可以支持多个级别的抽象(如边缘、纹理、对象、场景),同一个网络可以在无监督环境下,在单个前向传播过程中同时完成场景识别和目标定位。

图 14:估计每个神经元的感受野
针对每个神经元,作者估计出了其确切地感受野,并观察到激活区域倾向于随着层的深度增加而在语义上变得更有意义(这是启发后来一系列计算机视觉神经网络框架的理论基础)。
周博磊CVPR 2017[17]提出了一种名为“Network Dissection”的通用框架,假设“单元的可解释性等同于单元的随机线性结合”,通过评估单个隐藏单元与一系列语义概念间的对应关系,来量化 CNN 隐藏表征的可解释性。
这种方法利用大量的视觉概念数据集来评估每个中间卷积层隐藏单元的语义。这些带有语义的单元被赋予了大量的概念标签,这些概念包括物体、组成部分、场景、纹理、材料和颜色等。该方法揭示 CNN 模型和训练方法的特性,而不仅仅是衡量他们的判别能力。
论文发现:人类可解释的概念有时候会以单一隐藏变量的形式出现在这些网络中;当网络未受限于只能用可解释的方式分解问题时,就会出现这种内部结构。这种可解释结构的出现意味着,深度神经网络也许可以自发学习分离式表征(disentangled representations)。
众所周知,神经网络可以学习某种编码方式,高效利用隐藏变量来区分其状态。如果深度神经网络的内部表征是部分分离的,那么检测断分离式结构并读取分离因数可能是理解这种机制的一种方法。同时该论文指出可解释性是与坐标轴对齐(axis-aligned)的,对表示(representation)进行翻转(rotate),网络的可解释能力会下降,但是分类性能不变。越深的结构可解释性越好,训练轮数越多越好。而与初始化无关dropout会增强可解释性而Batch normalization会降低可解释性。
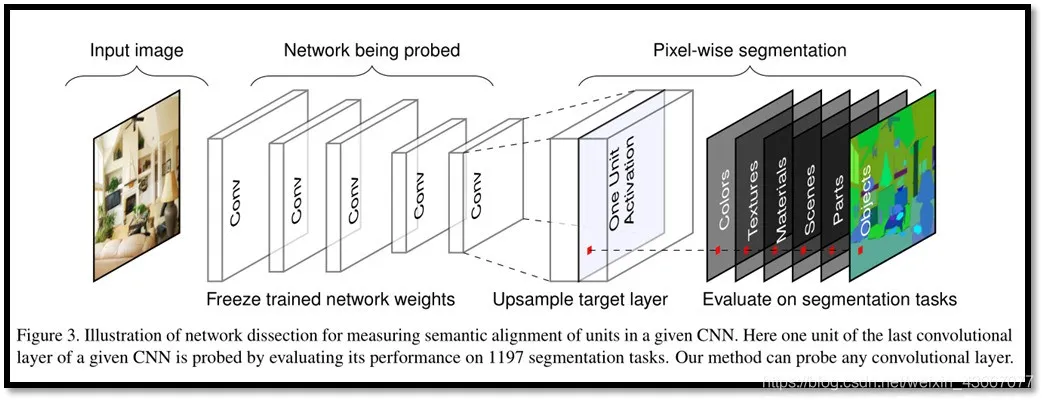
图 15
麻省理工大学CSAIL的Jonathan Frankle和Michael Carbin论文[18]中指出神经网络剪枝技术可以将受过训练的网络的参数减少90%以上,在不影响准确性的情况下,降低存储要求并提高计算性能。
然而,目前的经验是通过剪枝产生的稀疏架构很难从头训练,也很难提高训练性能。作者发现标准的剪枝技术自然而然地可以得到子网络,它们能在某些初始化条件下有效地进行训练。在此基础之上,作者提出了彩票假设:任何密集、随机初始化的包含子网络(中奖彩票)的前馈网络 ,当它们被单独训练时,可以在相似的迭代次数内达到与原始网络相当的测试精度。
具体而言,作者通过迭代式而定剪枝训练网络,并剪掉最小的权重,从而得到「中奖彩票」。通过大量实验,作者发现,剪枝得到的中奖彩票网络比原网络学习得更快,泛化性能更强,准确率更高。剪枝的主要的步骤如下:
(1)随机初始化一个神经网络
(2)将网络训练 j 轮,得到参数
(3)剪掉其中 p% 的参数,得到掩模 m
(4)将剩余的参数重置为中的值,生成中奖彩票
图 16:虚线为随机才应该能得到的稀疏网络,实现为中奖彩票。
此外,加利福尼亚大学的ZHANG Quanshi和ZHU Song-chun 综述了近年来神经网络可解释性方面的研究进展[19]。文章以卷积神经网络(CNN)为研究对象,回顾了CNN表征的可视化、预训练CNN表征的诊断方法、预训练CNN表征的分离方法、带分离表示的CNN学习以及基于模型可解释性的中端学习。
最后,讨论了可解释人工智能的发展趋势,并且指出了以下几个未来可能的研究方向:1)将conv层的混沌表示分解为图形模型或符号逻辑;2)可解释神经网络的端到端学习,其中间层编码可理解的模式(可解释的cnn已经被开发出来,其中高转换层中的每个过滤器代表一个特定的对象部分);3)基于CNN模式的可解释性表示,提出了语义层次的中端学习,以加快学习过程;4)基于可解释网络的语义层次结构,在语义级别调试CNN表示将创建新的可视化应用程序。
网络模型自身也可以通过不同的设计方法和训练使其具备一定的解释性,常见的方法主要有三种:注意力机制网络;分离表示法;生成解释法。基于注意力机制的网络可以学习一些功能,这些功能提供对输入或内部特征的加权,以引导网络其他部分可见的信息。分离法的表征可以使用单独的维度来描述有意义的和独立的变化因素,应用中可以使用深层网络训练显式学习的分离表示。在生成解释法中,深层神经网络也可以把生成人类可理解的解释作为系统显式训练的一部分。
2.3
生成自我解释的深度学习系统
网络模型自身也可以通过不同的设计方法和训练使其具备一定的解释性,常见的方法主要有三种:注意力机制网络;分离表示法;生成解释法。基于注意力机制的网络可以学习一些功能,这些功能提供对输入或内部特征的加权,以引导网络其他部分可见的信息。分离法的表征可以使用单独的维度来描述有意义的和独立的变化因素,应用中可以使用深层网络训练显式学习的分离表示。在生成解释法中,深层神经网络也可以把生成人类可理解的解释作为系统显式训练的一部分。
(1)注意力机制网络
注意力机制的计算过程可以被解释为:计算输入与其中间过程表示之间的相互权重。计算得到的与其他元素的注意力值可以被直观的表示。
在Dong Huk Park 发表于CVPR2018的[20]一文中,作者提出的模型可以同时生成图像与文本的解释。其方法在于利用人类的解释纠正机器的决定,但当时并没有通用的包含人类解释信息与图像信息的数据集,因此,作者整理了数据集ACT-X与VQA-X,并在其上训练提出了P-JX(Pointing and Justification Explanation)模型,检测结果如图所示。

图 17:P-JX模型检测结果
模型利用「attention」机制得到图像像素的重要性,并据此选择输出的视觉图,同时,数据集中的人类解释文本对模型的预测作出纠正,这样模型可以同时生成可视化的解释,亦能通过文字说明描述关注的原因。例如在上图中,对问题「Is this a healthy meal」,针对图片,关注到了热狗,因此回答「No」,图片的注意力热力图给出了可视化的解释,同时文本亦生成了对应的文本解释。作者认为,利用多模态的信息可以更好地帮助模型训练,同时引入人类的知识纠错有利于提高模型的可解释性。
由于类别之间只有通过细微局部的差异才能够被区分出来,因此「fine-grained」分类具有挑战性,在Xiao et. al. 的[21]中,作者将视觉「attention」应用到「fine-grained」分类问题中,尽管注意力的单元不是出于可解释性的目的而训练的,但它们可以直接揭示信息在网络种的传播地图,可以作为一种解释。由于细粒度特征不适用bounding box标注,因此该文章采用「弱监督学习」的知识来解决这一问题。
该文章中整合了3种attention模型:「bottom-up」(提供候选者patch),「object-level top-down」(certain object相关patch),和「part-level top-down 」(定位具有分辨能力的parts),将其结合起来训练「domain-specific深度网络」。
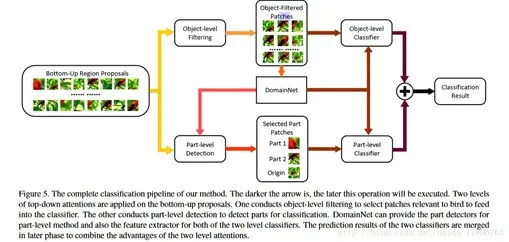
图 18:Domain-specific深度网络结构示意图
domain-specific深度网络结构示意图如图 18 所示:实现细粒度图像分类需要先看到物体,然后看到它最容易判别的部分。通过bottom-up生成候选patches,这个步骤会提供多尺度,多视角的原始图像。
如果object很小,那么大多数的patches都是背景,因此需要top-down的方法来过滤掉这些噪声patches,选择出相关性比较高的patches。寻找前景物体和物体的部分分别采用「object-level」和「part-level」两个过程,二者由于接受的patch不同,使其功能和优势也不同。在object-level中对产生的patches选出包含基本类别对象的patch,滤掉背景。part-level分类器专门对包含有判别力的局部特征进行处理。
有的patch被两个分类器同时使用,但该部分代表不同的特征,将每幅图片的object-level和part-level的分数相加,得到最终的分数,即分类结果。
(2)分离表示法
分离表示目标是用高低维度的含义不同的独立特征表示样本,过去的许多方法提供了解决该问题的思路,例如PCA、ICA、NMF等。深度网络同样提供了处理这类问题的方法。
Chen et. al. 在加州大学伯克利分校的工作[22]曾被 OpenAI 评为 2016 年 AI 领域的五大突破之一,在 GAN 家族的发展历史上具有里程碑式的意义。对于大多数深度学习模型而言,其学习到的特征往往以复杂的方式在数据空间中耦合在一起。如果可以对学习到的特征进行解耦,就可以得到可解释性更好的编码。对于原始的 GAN 模型而言,生成器的输入为连续的噪声输入,无法直观地将输入的维度与具体的数据中的语义特征相对应,即无法得到可解释的数据表征。为此,InfoGAN 的作者以无监督的方式将 GAN 的输入解耦为两部分:
(1)不可压缩的 z,该部分不存在可以被显式理解的语义信息。
(2)可解释的隐变量 c,该部分包含我们关心的语义特征(如 MNIST 数据集中数字的倾斜程度、笔画的粗细),与生成的数据之间具有高相关性(即二者之间的互信息越大越好)。
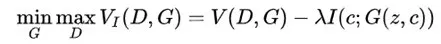
若 c 对生成数据 G(z,c)的可解释性强,则 c 与 G(z,c) 之间的交互信息较大。为了实现这一目标,作者向原始 GAN 的目标函数中加入了一个互信息正则化项,得到了如下所示的目标函数:
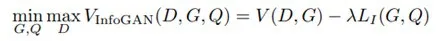
然而,在计算新引入的正则项过程中,模型难以对后验分布 P(C|X) 进行采样和估计。因此,作者采用变分推断的方法,通过变分分布 Q(C|X) 逼近 P(C|X)。最终,InfoGAN 被定义为了如下所示的带有变分互信息正则化项和超参数 λ 的 minmax 博弈:
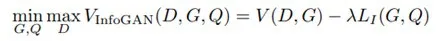

图 19:InfoGAN 框架示意图
张拳石团队的[23]一文中,提出了一种名为「解释图」的图模型,旨在揭示预训练的 CNN 中隐藏的知识层次。
在目标分类和目标检测等任务中,端到端的「黑盒」CNN模型取得了优异的效果,但是对于其包含丰富隐藏模式的卷积层编码,仍然缺乏合理的解释,要对 CNN 的卷积编码进行解释,需要解决以下问题:
CNN 的每个卷积核记忆了多少种模式?
哪些模式会被共同激活,用来描述同一个目标部分?
两个模式之间的空间关系如何?
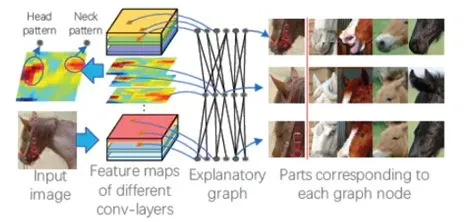
图 20:解释图结构示意图
解释图结构示意图表示了隐藏在 CNN 卷积层中的知识层次。预训练 CNN 中的每个卷积核可能被不同的目标部分激活。本文提出的方法是以一种无监督的方式将不同的模式从每个卷积核中解耦出来,从而使得知识表征更为清晰。
具体而言,解释图中的各层对应于 CNN 中不同的卷积层。解释图的每层拥有多个节点,它们被用来表示所有候选部分的模式,从而总结对应的卷积层中隐藏于无序特征图中的知识,图中的边被用来连接相邻层的节点,从而编码它们对某些部分的共同激活逻辑和空间关系。将一张给定的图像输入给 CNN,解释图应该输出:(1)某节点是否被激活(2)某节点在特征图中对应部分的位置。由于解释图学习到了卷积编码中的通用知识,因此可以将卷积层中的知识迁移到其它任务中。
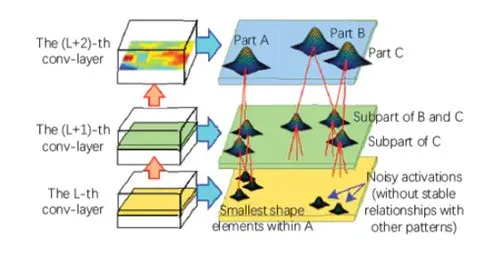
图 21:解释图中各部分模式之间的空间关系和共同激活关系图
解释图中各部分模式之间的空间关系和共同激活关系。高层模式将噪声滤除并对低层模式进行解耦。从另一个层面上来说,可以将低层模式是做高层模式的组成部分。
另外,张拳石[24]认为在传统的CNN中,一个高层过滤器可能会描述一个混合的模式,例如过滤器可能被猫的头部和腿部同时激活。这种高卷积层的复杂表示会降低网络的可解释性。针对此类问题,作者将过滤器的激活与否交由某个部分控制,以达到更好的可解释性,通过这种方式,可以明确的识别出CNN中哪些对象部分被记忆下来进行分类,而不会产生歧义。
模型通过对高卷积层的每个filter计算loss,种loss降低了类间激活的熵和神经激活的空间分布的熵,每个filter必须编码一个单独的对象部分,并且过滤器必须由对象的单个部分来激活,而不是重复地出现在不同的对象区域。
图 22
Hinton的胶囊网络 [25],是当年的又一里程碑式著作。作者通过对CNN的研究发现CNN存在以下问题:1) CNN只关注要检测的目标是否存在,而不关注这些组件之间的位置和相对的空间关系;2) CNN对不具备旋转不变性,学习不到3D空间信息;3)神经网络一般需要学习大量案例,训练成本高。为了解决这些问题,作者提出了「胶囊网络」,使网络在减少训练成本的情况下,具备更好的表达能力和解释能力。
「胶囊(Capsule)」可以表示为一组神经元向量,用向量的长度表示物体「存在概率」,再将其压缩以保证属性不变,用向量的方向表示物体的「属性」,例如位置,大小,角度,形态,速度,反光度,颜色,表面的质感等。
和传统的CNN相比,胶囊网络的不同之处在于计算单位不同,传统神经网络以单个神经元作为单位,capsule以一组神经元作为单位。相同之处在于,CNN中神经元与神经元之间的连接,capsNet中capsule与capsule之间的连接,都是通过对输入进行加权的方式操作。
胶囊网络在计算的过程中主要分为四步:
输入向量ui的W矩阵乘法;
输入向量ui的标量权重c;
加权输入向量的总和;
向量到向量的非线性变换。
网络结构如下图所示,其中「ReLI Conv1」是常规卷积层;「PrimaryCaps」构建了32个channel的capsules,得到6*6*8的输出;「DigiCaps」对前面1152个capules进行传播与「routing」更新,输入是1152个capsules,输出是10个capules,表示10个数字类别,最后用这10个capules去做分类。
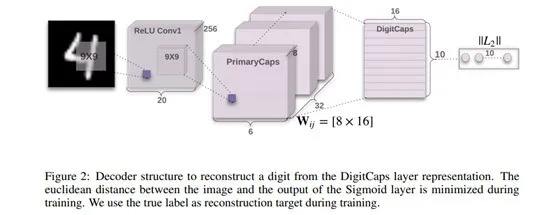
图23:胶囊网络网络结构示意图
(3)生成解释法
除了上文介绍的诸多方法外,在模型训练的同时,可以设计神经网络模型,令其产生能被人类理解的证据,生成解释的过程也可被显式地定义为模型训练的一部分。
Wagner 2019[26]首次实现了图像级别的细粒度解释。文中提出的「FGVis」,避免了图像的可解释方法中对抗证据的问题,传统方法采用添加正则项的方式缓解,但由于引入了超参,人为的控制导致无法生成更加可信的,细粒度的解释。文中的FGVis方法基于提出的「对抗防御(Adversarial Defense)」方法,通过过滤可能导致对抗证据的样本梯度,从而避免这个问题。该方法并不基于任何模型或样本,而是一种优化方法,并单独对生成解释图像中的每个像素优化,从而得到细粒度的图像解释,检测示意图如图[24] 所示。

图24:FGVis检测结果示意图
另一个视觉的例子来自Antol et. 的Vqa[27],文章将视觉问题的「回答任务(Vqa)」定义为给定一个图像和一个开放式的、关于图像的自然语言问题,并提出了Vqa的「基准」和「回答方法」,同时还开发了一个两通道的视觉图像加语言问题回答模型。
文章首先对Vqa任务所需的数据集进行采集和分析,然后使用baselines为「基准」对「方法」进行评估,基准满足4个条件:1) 随机,2)答案先验, 3)问题先验,4)最近邻。
「方法」使用文中开发的两个视觉(图像)通道加语言(问题)通道通过多层感知机结合的模型,结构图如图所示。视觉图像通道利用 VGGNet最后一层隐藏层的激活作为 4096- dim 图像嵌入,语言问题通道使用三种方法嵌入:
构建「词袋问题(BoW Q)」;
「LSTM Q 」具有一个隐藏层的lstm对1024维的问题进行嵌入;
「deeper LSTM Q」。最终使用softmax方法输出K个可能的答案。
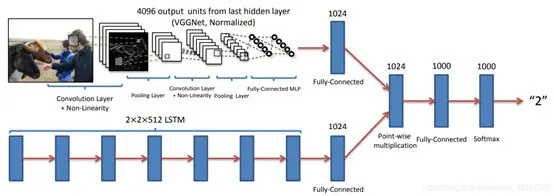
图 25:deeper LSTM Q + norm I 结构图
三. 总结
为了使深度学习模型对用户而言更加「透明」,研究人员近年来从「可解释性」和「完整性」这两个角度出发,对深度学习模型得到预测、决策结果的工作原理和深度学习模型本身的内部结构和数学操作进行了解释。至今,可解释性深度学习领域的研究人员在「网络对于数据的处理过程」、「网络对于数据的表征」,以及「如何构建能够生成自我解释的深度学习系统」三个层次上均取得了可喜的进展:
- 就网络工作过程而言,研究人员通过设计线性代理模型、决策树模型等于原始模型性能相当,但具有更强可解释性的模型来解释原始模型;此外,研究人员还开发出了显著性图、CAM 等方法将于预测和决策最相关的原始数据与计算过程可视化,给出一种对深度学习模型的工作机制十分直观的解释。
- 就数据表征而言,现有的深度学习解释方法涉及「基于层的解释」、「基于神经元的解释」、「基于表征向量的解释」三个研究方向,分别从网络层的设计、网络参数规模、神经元的功能等方面探究了影响深度学习模型性能的重要因素。
- 就自我解释的深度学习系统而言,目前研究者们从注意力机制、表征分离、解释生成等方面展开了研究,在「视觉-语言」多模态任务中实现了对模型工作机制的可视化,并且基于 InfoGAN、胶囊网络等技术将对学习有不同影响表征分离开来,实现了对数据表征的细粒度控制。
然而,现有的对深度学习模型的解释方法仍然存在诸多不足,面临着以下重大的挑战:
- 现有的可解释性研究往往针对「任务目标」和「完整性」其中的一个方向展开,然而较少关注如何将不同的模型解释技术合并起来,构建更为强大的模型揭示方法。
- 缺乏对于解释方法的度量标准,无法通过更加严谨的方式衡量对模型的解释结果。
- 现有的解释方法往往针对单一模型,模型无关的解释方法效果仍有待进一步提升。
- 对无监督、自监督方法的解释工作仍然存在巨大的探索空间。


